Most commercial LLM (Large Language Model) systems provide paid APIs that allow the creation of applications such as chatbots, virtual assistants, copilots, and more.
However, using commercial systems like GPT-4, Bert, or Transformer presents challenges that limit their use in customized applications, i.e., specialized applications related to a specific domain:
- The cost of queries increases with the amount of data sent (measured in tokens) and the number of queries.
- The number of tokens (amount of data sent) per query is limited.
- The data available to LLMs is not up-to-date.
- If you have a huge amount of data to consult, related to a specific domain and coming from different sources (databases, documents, RSS feeds, REST APIs, etc.), it is not possible to fully leverage it.
- It is necessary to send the LLM system all the data needed to answer a question, even if it is confidential.
- Responses are subject to hallucinations, especially if the data to answer a question is missing or insufficient.
- There is no way to know which sources were used to generate a response.
Therefore, an architectural model called RAG (Retrieval Augmented Generation) [1] [2] was developed, which, by introducing preliminary phases before using LLMs, solves the issues mentioned above, particularly allowing the use of updated data from any data source and reducing the number of queries sent to the LLM.
The idea is to:
- store all necessary data in a vector database,
- extract from it the information needed to answer a question,
- send this information as context along with the question itself to the LLM in a properly structured prompt,
- retrieve and use the response generated by the LLM system using this prompt.
This way, the LLM is only required to produce an answer based on a prompt containing the question and a context made up of the retrieved information from your systems.
How the RAG Model Works
A RAG system essentially consists of two components: a Retriever and a Generator that perform the following functions:
RETRIEVER
- Document Loading: Reading and loading data from all available sources, using specific connectors and readers depending on the data source: databases, RSS feeds, PDF files, web services, etc.
- Splitting (Chunking): Dividing documents into smaller, more manageable units, aiming to create meaningful units. Each chunk can be associated with metadata that allows tracing back to the sources of a response.
- Embedding: Each “piece of information” is transformed into numerical vectors; this encoding is necessary for the next step.
- Storage (Embeddings storage): The numerical vectors, containing all encoded information, are saved in a vector database, which is optimized to handle vector data.
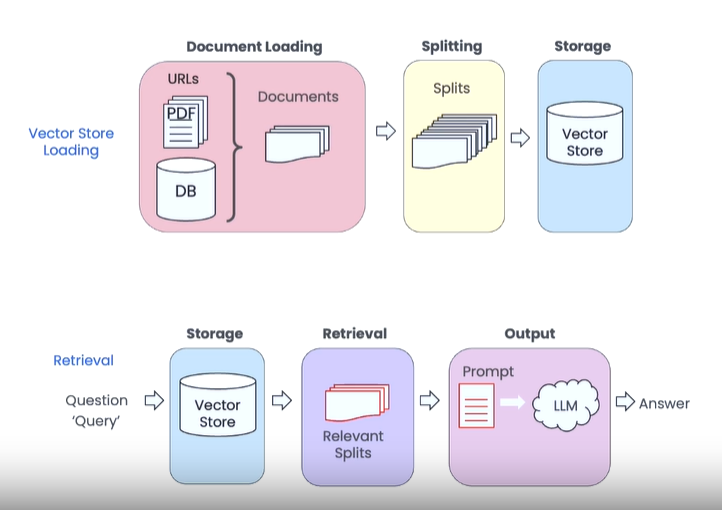
GENERATOR
When the system is asked to answer a question (Query), the steps are as follows:
- Retrieval: The Query is sent to the vector database, which transforms it into a vector and, after comparison, returns compatible vectors, i.e., the “pieces of information” relevant to answering that question.
- Prompt: A prompt is prepared where the question is the user’s Query and the context consists of the “pieces of information” retrieved in the previous step.
- Output generation: The prompt is sent to the LLM, which processes it and produces a response as the result.
Since each data chunk is associated with metadata, it is possible to trace back the sources used to generate a response.
Using this system, it is likely that the data retrieved during the Retrieval phase will be large and cannot fit into a single prompt. Various techniques exist to handle this scenario, including further filtering of data or multiple requests to the LLM, either sequentially or in parallel. However, it is better to address this topic in a dedicated post.
Available Frameworks
To implement a RAG system, you can use frameworks and systems that perform the actions described above:
- RAG Frameworks:
- LangChain: an open-source framework for developing applications using LLMs, such as chatbots and virtual agents, through tools and APIs available in Python and JavaScript libraries. LangChain allows representing complex processes as modular components. These components can then be chained to build more or less complex applications. The main tools offered by the framework are: Models, Prompt, Parser, Chains, Agents, etc.
- LLamaIndex: a framework that enables retrieving and structuring private or domain-specific data and efficiently using it in customized applications. It offers tools to retrieve data from various sources, index and store it in vector databases, query vector databases, prepare structured prompts, and query LLMs.
- Vector Databases:
-
- Pinecone
- Qdrant
- Milvus
- Weaviate
- ElasticSearch
- Chroma
-
- Large Language Models:
- GPT-4
- Bert
- Transformer
Useful Courses
DeepLearning.AI offers a series of mini-courses that introduce the use of LLMs (for example, GPT-4) and the development of RAG applications (for example, LangChain, LLamaIndex, etc.).
The courses are often taught by the creators of the frameworks themselves and are coordinated by Andrew Ng, one of the leading experts in AI and neural networks, as well as an excellent educator.
Possible In-Depth Posts to Create
I would like to explore these topics soon:
- How to run an LLM locally: Running an LLM model locally with Ollama, How to run an LLM model locally with LM Studio.
- A graphical interface for Ollama: OpenWeb UI.
- Building a RAG system with Open Web UI and Ollama: ChefGino project.
- Fine-tuning a model vs RAG systems.
- How to build a RAG with LlamaIndex.
- Vector databases and ChromaDB.
Stay tuned!!!
Sources and References
- [1] Retrieval-Augmented Generation for Large Language Models: A Survey – Yunfan Gao, Yun Xiong, et al.
- [2] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks – Patrick Lewis, Ethan Perez, et al.
- [3] A Cheat Sheet and Some Recipes For Building Advanced RAG – Andrei on LlamaIndex Blog.
- [4] High-Level concepts: Retrieval Augmented Generation (RAG) – LlamaIndex documentation.
- [5] LangChain for LLM Application Development – Andrew Ng and Harrison Chase on DeepLearning.ai.
- [6] LangChain Chat with Your Data – Andrew Ng and Harrison Chase on DeepLearning.ai.
- [7] Building and Evaluating Advanced RAG with LlmaIndex – Andrew Ng, Jerry Liu, and Anupam Datta on DeepLearning.ai.
- [8] Vector Databases: from Embeddings to Applications – Andrew Ng and Sebastian Witalec on DeepLearning.ai.
- [9] Vector Databases for A.I. – HPA on Medium.com.
- [10] RAG: The link between pre-trained language models and real-time data by ZBrain.
- [11] What is the Difference Between LlamaIndex and LangChain by Jeff.
- [12] Short Courses by DeepLearning.AI.
- [13] LangChain – official site.
- [14] LlamaIndex – official site.
*** Note: This article was translated using an automated workflow built with n8n and OpenAI.