大多数商业LLM(大型语言模型)系统提供付费API,允许开发诸如聊天机器人、虚拟助手、协同助手等应用。
然而,使用商业系统如GPT-4、Bert或Transformer存在一些限制,影响其在定制化应用中的使用,即针对特定领域的专业应用:
- 查询成本随着发送的数据量(以token计)和查询次数增加而上升。
- 每次查询可发送的token数量有限制。
- LLM所依赖的数据并非实时更新。
- 如果拥有大量来自不同来源(数据库、文档、RSS订阅、REST API等)的特定领域数据,无法充分利用这些数据。
- 必须向LLM系统发送所有回答问题所需的数据,即使这些数据是敏感的。
- 回答可能出现幻觉,尤其是在缺乏或数据不足时。
- 无法追踪生成回答所依据的具体数据来源。
因此,出现了一种架构模型称为RAG(检索增强生成) [1] [2] ,通过在使用LLM之前引入预处理阶段,解决上述问题,特别是允许使用来自任何数据源的实时更新数据,并减少对LLM的查询次数。
其核心思想是:
- 将所有必要数据存储在向量数据库中,
- 从中提取回答问题所需的信息,
- 将这些信息作为上下文与问题一起构建成提示,发送给LLM,
- 获取并使用LLM基于该提示生成的回答。
这样,LLM只需基于包含问题和检索到的上下文信息的提示生成回答。
RAG模型的工作原理
RAG主要由两个组件组成:一个检索器(Retriever)和一个生成器(Generator),它们的功能如下:
检索器(RETRIEVER)
- 文档加载:从所有可用数据源读取并加载数据,使用针对不同数据源(数据库、RSS订阅、PDF文件、网络服务等)的专用连接器和读取器。
- 拆分(分块):将文档分割成更小且易于管理的单元,尽量保证每个单元语义完整。每个分块可关联元数据,便于追溯回答的来源。
- 嵌入(Embedding):将每个“信息片段”转换为数字向量,这种编码便于后续处理。
- 存储(嵌入存储):将包含编码信息的数字向量保存到向量数据库,这是一种针对向量数据优化的数据库。
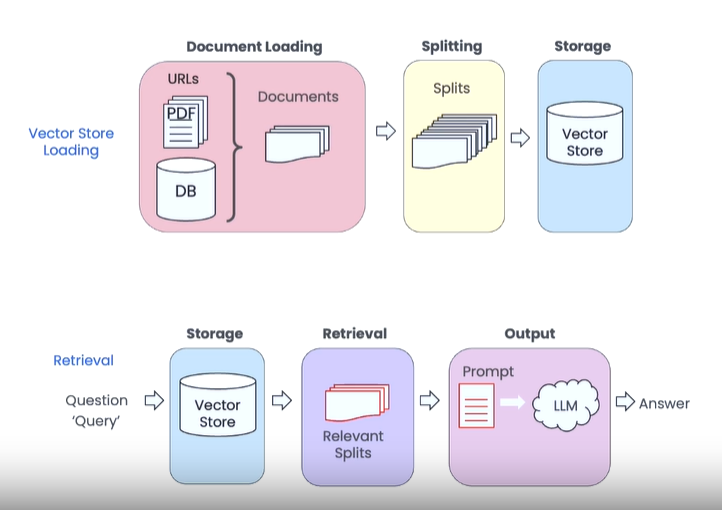
生成器(GENERATOR)
当系统被要求回答一个问题(查询)时,流程如下:
- 检索:将查询发送到向量数据库,数据库将其转换为向量,并通过比较返回相关向量,即与该问题相关的信息片段。
- 提示构建:准备一个提示,用户的问题作为查询,上下文由前一步检索到的“信息片段”组成。
- 输出生成:将提示发送给LLM,LLM处理后生成回答,作为最终结果。
由于每个数据分块都关联元数据,因此可以追踪生成回答所用的具体数据来源。
在检索阶段,可能会检索到大量数据,无法全部包含在一个提示中。对此,有多种技术方案,包括对数据进行进一步筛选,或分多次(顺序或并行)向LLM发起请求。此话题适合在专门的文章中详细讨论。
可用框架
实现RAG系统时,可以使用以下框架和系统来完成上述步骤:
- RAG框架:
- LangChain:一个开源框架,用于开发基于LLM的应用,如聊天机器人和虚拟代理,提供Python和JavaScript库中的工具和API。LangChain支持将复杂流程模块化表示,这些模块可以串联起来构建复杂应用。主要工具包括:Models、Prompt、Parser、Chains、Agents等。
- LLamaIndex:该框架支持检索和结构化私有或领域特定数据,并高效应用于定制化应用。提供工具用于从多源获取数据、索引并存储到向量数据库、查询向量数据库、准备结构化提示并调用LLM。
- 向量数据库:
-
- Pinecone
- Qdrant
- Milvus
- Weaviate
- ElasticSearch
- Chroma
-
- 大型语言模型:
- GPT-4
- Bert
- Transformer
推荐课程
DeepLearning.AI提供一系列迷你课程,介绍如何使用LLM(如GPT-4)以及构建RAG应用(如LangChain、LLamaIndex等)。
课程通常由框架的创建者授课,由Andrew Ng协调,他是AI和神经网络领域的顶尖专家,也是优秀的科普者。
未来拟深入探讨的主题
我计划近期深入研究以下内容:
- 如何在本地运行LLM:使用Ollama在本地运行LLM模型,使用LM Studio在本地运行LLM模型。
- Ollama的图形界面:OpenWeb UI。
- 使用Open Web UI和Ollama构建RAG系统:ChefGino项目。
- 模型微调与RAG系统的比较。
- 如何使用LlamaIndex构建RAG。
- 向量数据库与ChromaDB。
敬请期待!!!
参考资料
- [1] Retrieval-Augmented Generation for Large Language Models: A Survey – Yunfan Gao, Yun Xiong 等。
- [2] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks – Patrick Lewis, Ethan Perez 等。
- [3] A Cheat Sheet and Some Recipes For Building Advanced RAG – Andrei,LlamaIndex博客。
- [4] High-Level concepts: Retrieval Augmented Generation (RAG) – LlamaIndex文档。
- [5] LangChain for LLM Application Development – Andrew Ng 和 Harrison Chase,DeepLearning.ai。
- [6] LangChain Chat with Your Data – Andrew Ng 和 Harrison Chase,DeepLearning.ai。
- [7] Building and Evaluating Advanced RAG with LlmaIndex – Andrew Ng, Jerry Liu 和 Anupam Datta,DeepLearning.ai。
- [8] Vector Databases: from Embeddings to Applications – Andrew Ng 和 Sebastian Witalec,DeepLearning.ai。
- [9] Vector Databases per l’A.I. – HPA,Medium.com。
- [10] RAG: The link between pre-trained language models and real-time data,ZBrain。
- [11] What is the Difference Between LlamaIndex and LangChain,Jeff。
- [12] Short Courses,DeepLearning.AI。
- [13] LangChain – 官方网站。
- [14] LlamaIndex – 官方网站。
*** 本文由n8n和OpenAI自动翻译生成。