
E’ possibile sviluppare delle applicazioni che interrogano i sistemi LLM (Large Language Model) commerciali utilizzando delle API RHTTP/REST o delle librerie Python o TypeScript in modo da poter aggiungere delle funzionalità orginali, utili ed avanzate ai propri prodotti.
L’uso di questi sistemi commerciali comporta però alcune problematiche che possono costituire dei limiti importanti e che vanno affrontate, per esempio:
- Il costo delle interrogazioni o dell’abbonamento ai servizi come ChatGPT di OpenAI o come Claude di Anthropic,
- La privacy e quindi la fuoriuscita di dati strategici o sensibili al di fuori di una organizzazione verso multinazionali straniere.
- L’impossibilità di utilizzare questi sistemi in modalità offline.
- Il rischio di lock-in, ossia di legarsi a una società terza e di dipendera dalle sue scelte commerciali.
Per questo è utile eseguire un modello LLM sui server dell’organizzazione o su un cloud privato, e infatti già sono disponibili diverse tecnologie che permettono di utilizzare dei modelli open-source in contesti privati e protetti. Solo in questo modo si può avere il controllo completo del proprio sistema.
C’è anche un modo semplice e gratuito per fare dei test e delle prove sul proprio PC, si tratta di LM Studio, che è appunto, una applicazione desktop gratuita e multi piattaforma che permette di scaricare, eseguire e interrogare degli LLM.
Installazione e configurazione
LM Studio è disponibile per sistemi Linux, Apple e Windows. Su Windows, basta scaricare il pacchetto di installazione dal sito ufficiale [1] ed eseguirlo.
Una volta installato, l’interfaccia che si presenta all’utente è la seguente:

Per prima cosa è necessario scegliere e scaricare un modello cliccando sulla lentina (Discover) presente nella barra a sinistra:
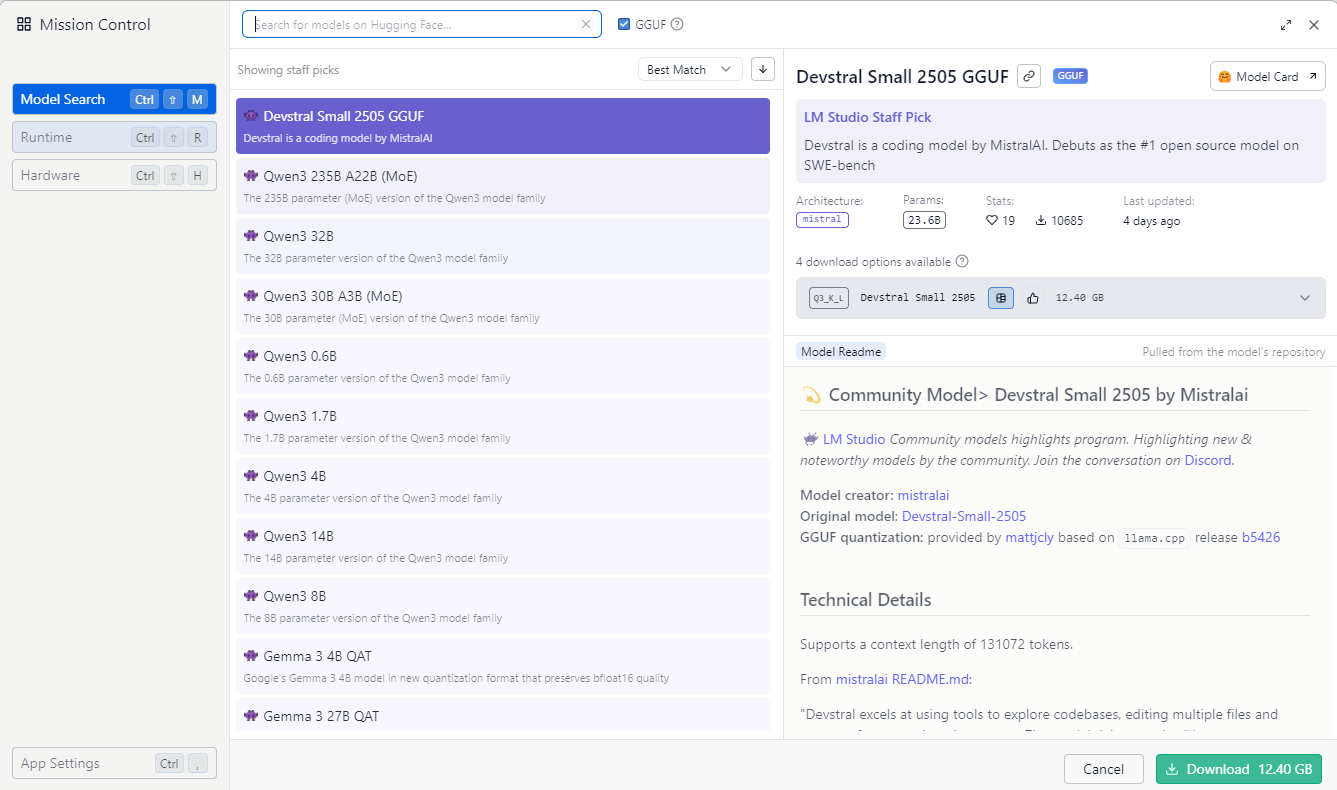
Per ogni modello presente nell’elenco, sono indicate varie informazioni: il nome, l tipo di architettura, il numero di parametri, il numero di download, i dettagli tecnici, la data di creazione e, soprattuto, se le risorse del proprio computer sono sufficienti ad eseguire quel modello.
Si potrebbe, per esempio, provare a cercare e scaricare il modello DeepSeek o il modello Phi 3 mini di Microsoft.
Dopo averlo scaricato in locale, il modello va caricato selezionando nel menu che compare nella parte alta della finestra principale del programma.
Terminato il caricamento è possibile interrogarlo, utilizzando l’interfaccia dell’applicazione come siamo abituati a fare con i servizi commerciali online. E’ perfino possibile anche arricchire la propria richiesta con degli allegati.
Cos’è un modello?
Un modello è una rete neurale di tipo Transformer già addestrata e distribuita in un formato ottimizzato per essere eseguito localmente anche con hardware consumer.
In pratica sono dei file binari che possono avere vari formati (nel caso di LM Studio il formato è GGUF [4]) e che contengono: le matrici dei pesi, la struttura della rete codificata, gli stati appresi durante l’addestramento, ecc.
Nel nome del modello ci sono dei codici che indicano il numero di parametri utilizzati che sono in relazione con la complessità della rete e con la dimensione del file:
| Sigla / Suffisso | # Parametri | Dimensione indicativa del file GGUF * | Esempio |
| 350M | 350 milioni | ~300 MB / ~400 MB | Minerva-350M-base-v1.0-Q8_0-GGU |
| 1.3B | 1,3 miliardi | ~1 GB / ~2 GB | deepseek-coder-1.3b-instruct-GGUF |
| 3.1B | 3,1 miliardi | ~1,2 GB / ~7 GB | Phi 3.1 Mini 128k |
| 7B | 7 miliardi | ~3 GB / ~13 GB | DeepSeek R1 Distill Qwen 7B |
| 65B | 65 miliardi | ~30 GB / ~130 GB | LLaMA-65B-GGUF |
* La dimensione del file varia a seconda della quantizzazione, per esempio: Q4_0, Q4_K_M, Q6_K, Q8_0, FP16, Q5, Q5_K_M sono dei livelli possibili.
La quantizzazione, nei modelli di deep learning, è una tecnica di compressione che serve a ridurre le dimensioni e i requisiti computazionali del modello, rendendolo più veloce ed efficiente, specialmente su dispositivi con risorse limitate (come smartphone, portatili o microcontrollori). I formati Q4_K_M e Q6_K rappresentano, al momento, il miglior compromesso tra dimensioni del file e qualità delle prestazioni.
Modalità di operative e modalità di interazione
Da interfaccia si possono attivare tre modalità operative: User, Power User e Developer. Ognuna di queste permette di attivare delle configurazioni più o meno complesse in base alle proprie competenze. La terza modalità permette di avviare un server accessibile il cui scopo è quello di permettere ad applicazioni esterne di interagire con il modello con API HTTP o tramite una libreria.
Quindi, riassumendo, è possibile interagire con un modello eseguito da LM Studio in tre diversi modi:
- Tramite l’interfaccia utente: interazione classica.
- Tramite una API HTTP: molto utile per applicazioni web.
- Tramite una libreria Python o TypeScript: utile per la realizzazione di moduli, agenti o applicazioni di vario genere.
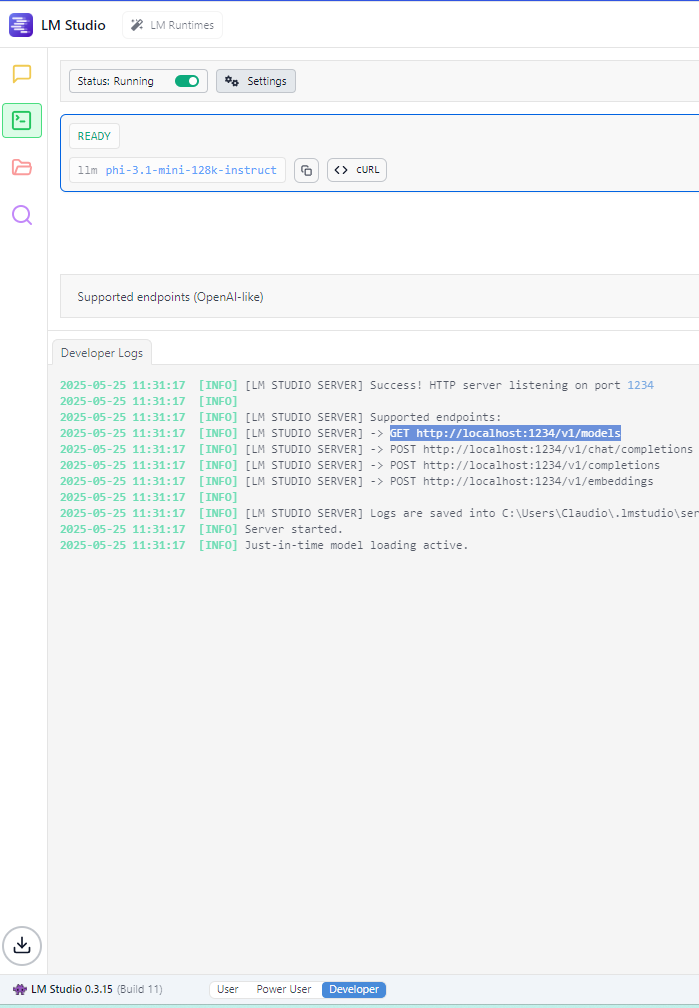
Per avviare il server di LM Studio, dopo aver sceltro la modalità Developer nella parte bassa della maschera principale, basta cliccare sull’icona verde “prompt” (Developer) che compare nella barra di sinistra e poi avviarlo con il pulsante presente nella sezione Status:
Interazione tramite l’API HTTP
Dopo aver avviato il server di LM Studio, che di default si metterà in ascolto sulla porta 1234, si possono realizzare delle chiamate HTTP usando il browser, il comando curl, un programma come Insomnia o il linguaggio di programmazione preferito.
Per esempio, con il browser si può usare questo URL per vedere l’elenco dei modelli scaricati: http://localhost:1234/v1/models.
Oppure con il comando CURL è possibile interrogare il modello in questo modo:
curl http://localhost:1234/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"phi-3.1-mini-128k-instruct\", \"messages\": [{\"role\": \"user\", \"content\": \"Cos'è un capibara?\"}], \"temperature\": 0.7}"
Interazione con Python tramite la libreria lmstudio
Per interrogare il modello utilizzando Python, invece, è necessario installare la libreria lmstudio:
pip install lmstudio
e poi eseguire il codice seguente:
import lmstudio as lm
model = lm.llm("deepseek-r1-distill-qwen-7b")
prediction = model.respond("Spiegami la relatività ristretta in parole semplici.")
print(prediction)
oppue il seguente:
import lmstudio as lm
model = lm.llm("deepseek-r1-distill-qwen-7b")
prediction = model.respond_stream("Cos'è un Capybara?")
for fragment in prediction:
print(fragment.content, end="", flush=True)
print()
Con TypeScript cambia la sintassi, ma il modo d’interazione è simile.
Interazione tramite la console
E’ possibile interagire con il server anche a linea di comando, tramite una console integrata in LM Studio, usando il comando lms.
Alcuni esempi di comandi utilizzabili:
lms version
lms ls
lms load phi-3.1-mini-128k-instruct
lms ps
lm server start
lm server stop
...
Galleria di immagini
Qui di seguito alcuni screenshot delle configurazioni e delle prove descritte in questo post:














Fonti e riferimenti
- LM Studio AI: sito ufficiale.
- Documentazione ufficiale di LM Studio.
- Come utilizzare le AI Generative in Locale su PC: LM Studio, Ollama e modelli Open Source, Lore Cloud su Youtube.
- Formato GGUF sul sito Hugging Face.
- Interrogare Bard / PaLM di Google con Python, su questo blog.
- Interrogare ChatGPT di OpenAI con Python, su questo blog.